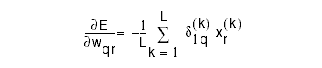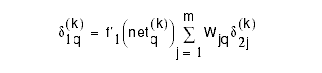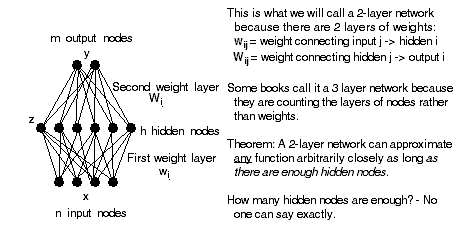
Error-Backpropagation
Much early research in networks was
abandoned because of the severe limitations of single layer linear networks.
Multilayer networks were not "discovered" until much later but even then there
were no good training algorithms. It was not until the `80s that backpropagation
became widely known.
People in the field joke about this because backprop is
really just applying the chain rule to compute the gradient of the cost
function. How many years should it take to rediscover the chain rule?? Of
course, it isn't really this simple. Backprop also refers to the very efficient
method that was discovered for computing the gradient.
Note: Multilayer nets are much harder to train than single layer networks. That is, convergence is much slower and speed-up techniques are more complicated.
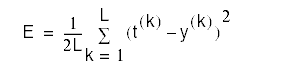
![]()
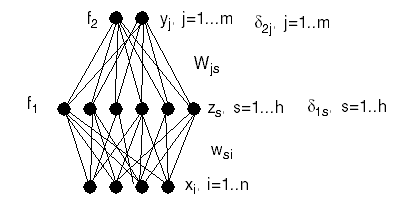
and where
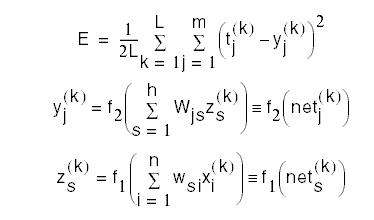
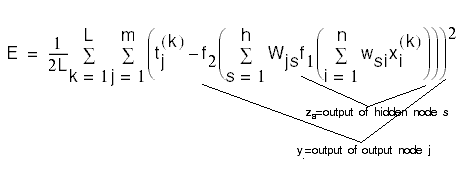
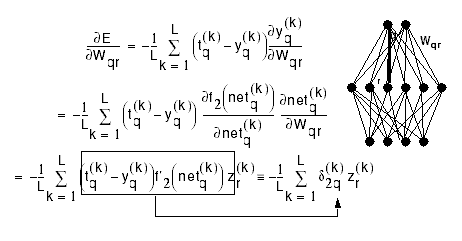
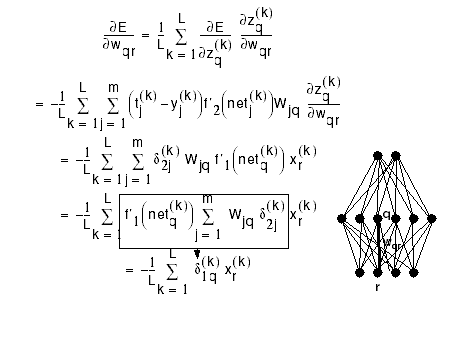
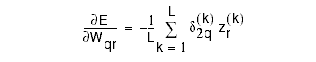
![]()